llmware
综合介绍
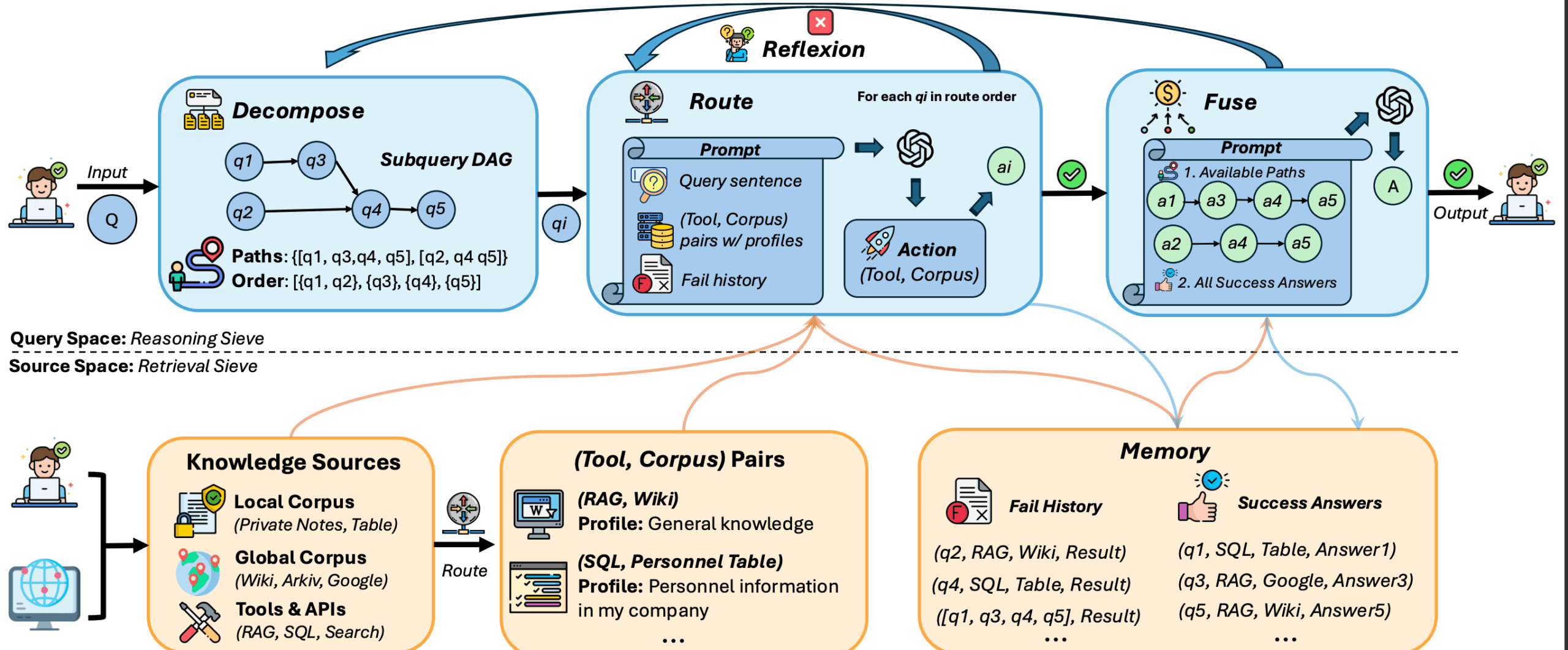
llmware是一个专为构建企业级大语言模型(LLM)应用而设计的Python开发框架。它的核心目标是让开发者能够安全、高效地将企业内部的私有知识库与大语言模型连接起来。这个框架通过提供一整套标准化的工具,覆盖了从数据处理到模型推理的整个流程,也就是我们常说的“检索增强生成”(RAG)技术。llmware最大的特点是它推崇使用一系列小型的、经过特殊优化的模型。这些模型可以直接部署在企业自己的服务器甚至普通笔记本电脑上,不需要依赖外部的API服务。这样做的好处是,所有的数据,包括敏感的商业文件,都保留在企业内部,从而极大地保证了数据的私有性和安全性。它主要由两个部分构成:一个是强大的RAG(检索增强生成)管道,负责解析各类文档、进行文本分块、创建向量索引等;另一个是包含超过50个小型专业化模型的模型库,这些模型专门针对问答、摘要、分类等企业级任务进行了微调,能够以较低的成本实现高效的自动化流程。
功能列表
- 统一的模型目录 : 提供一个名为
ModelCatalog的模型管理器,统一了访问和调用不同类型模型的方式。无论是llmware自家的优化模型(如BLING、DRAGON系列),还是来自HuggingFace、Sentence Transformers的开源模型,甚至是GGUF格式的本地模型,都可以通过一致的接口加载和使用。 - 强大的文档解析能力 : 支持多种常见的企业文档格式,包括PDF、Word(.docx)、PowerPoint(.pptx)、Excel(.xlsx),以及文本、图片和音频文件。它可以自动从这些文件中提取文本、表格和图片内容。
- 灵活的知识库管理 (Library) : 提出了“知识库”(Library)的概念,作为一个容器来管理和索引知识。用户可以轻松创建一个知识库,然后将整个文件夹的文档批量添加进去。系统会自动完成解析、文本分块和建立索引,为后续的检索做好准备。
- 多功能的检索系统 (Query) : 支持多种检索方式。用户可以进行基本的文本搜索,也可以进行基于向量的语义搜索,或是将两者结合起来进行混合搜索,以获得更精准的检索结果。
- 简化的RAG流程 (Prompt with Sources) : 提供
Prompt类,极大地简化了构建RAG应用的复杂度。开发者只需几行代码,就可以将检索到的相关信息(即“知识源”)和用户的问题一起打包,发送给大语言模型进行处理,从而生成有理有据的回答。 - 数据存储的灵活性 : 在数据存储方面提供了极高的灵活性。文本和元数据可以存储在SQLite(默认,无需安装)、MongoDB或PostgreSQL中。而向量数据则支持ChromaDB(默认,无需安装)、Milvus、PGVector、FAISS等多种主流向量数据库。
- 专为企业优化的模型 : 提供一系列小型的(10亿到70亿参数)语言模型,这些模型经过专门微调,专注于企业场景下的特定任务,如事实问答、信息提取等。它们可以在没有GPU的普通CPU设备上高效运行。
- Agent与函数调用 : 引入了名为
LLMfx的Agent框架,可以将小型模型作为“工具”进行组合,完成更复杂的多步骤任务,例如对一段文本同时进行情感分析、主题提取和摘要生成。
使用帮助
llmware是一个功能强大的Python库,让开发者可以快速上手构建基于自有数据的AI应用。下面将详细介绍其安装和核心使用流程。
1. 安装
llmware的安装非常简单,通过pip命令即可完成。它提供了两种安装选项:
- 核心安装 (推荐初学者使用): 只安装最基础的依赖项,保证核心功能可用。
pip install llmware - 完整安装 : 安装所有可选的依赖项,支持更多的数据库和功能。
pip install 'llmware[full]'
对于大多数用户来说,核心安装已经足够开始探索llmware的功能。
2. 核心概念与基础RAG流程
使用llmware构建一个完整的RAG应用,通常会涉及到以下几个核心概念和步骤。下面的例子将演示如何从零开始,建立一个可以回答特定文档内容问题的简单程序。
场景 :假设你有一个名为“我的项目”的文件夹,里面存放着各种项目相关的PDF和Word文档。你希望构建一个程序,让它可以根据这些文档的内容,回答你的提问。
代码实现 :
import os
from llmware.library import Library
from llmware.retrieval import Query
from llmware.prompts import Prompt
from llmware.setup import Setup
# --- 第1步:创建知识库 (Library) ---
# 知识库是存放和管理你的文档的地方。
# 我们创建一个名为 "project_lib" 的新知识库。如果这个库已经存在,系统会自动加载它。
print("创建或加载知识库...")
library = Library().create_new_library("project_lib")
# --- 第2步:添加文档 ---
# 将你的本地文件夹路径告诉llmware。
# 这里我们使用llmware提供的示例文件作为演示。
# 在实际应用中,你应该替换成你自己的文件夹路径,例如 "/Users/username/Documents/我的项目/"
print("添加文档...")
# load_sample_files()会下载一些示例文件并返回其路径
sample_files_path = Setup().load_sample_files()
# 我们只添加其中的 "Agreements" 文件夹作为示例
documents_path = os.path.join(sample_files_path, "Agreements")
library.add_files(documents_path)
# --- 第3步:安装嵌入模型 (Embedding) ---
# 为了让机器能够理解文本的语义,我们需要为知识库中的文档创建“嵌入”(Embedding)。
# 这个过程只需要执行一次。
# 我们选择一个轻量级的嵌入模型和本地向量数据库ChromaDB。
# 这意味着你不需要安装任何额外的数据库软件。
embedding_model = "mini-lm-sbert"
vector_db = "chromadb"
print(f"为知识库安装嵌入模型:{embedding_model}...")
# get_embedding_status()会检查是否已经有名为 "project_lib" 的嵌入
if not library.get_embedding_status():
library.install_new_embedding(embedding_model_name=embedding_model, vector_db=vector_db)
else:
print("嵌入模型已安装。")
# --- 第4步:进行语义检索 (Query) ---
# 现在知识库已经准备就绪,我们可以开始提问了。
# 比如,我们想知道“高管的基本工资是多少?”
user_query = "What is the executive's base salary?"
print(f"\n正在进行语义检索,问题: '{user_query}'")
# 创建一个Query对象,并绑定到我们的知识库
query_handler = Query(library)
# 使用 semantic_query 方法进行语义搜索,找出最相关的5个文本片段
query_results = query_handler.semantic_query(user_query, result_count=5)
# 打印检索结果,让你了解模型看到了哪些上下文
print("\n检索到的相关文本片段:")
for i, result in enumerate(query_results):
print(f"片段 {i+1}: {result['text']}")
# --- 第5步:使用LLM生成最终回答 ---
# 检索到的文本片段是原始材料,我们需要一个大语言模型来阅读这些材料并生成一个自然的回答。
# llmware提供了许多可以在CPU上运行的小型模型。我们选择 "bling-phi-3-gguf"。
print("\n加载本地LLM并生成回答...")
# 创建一个Prompt对象,并加载模型
# temperature=0.0 表示我们希望模型给出更具确定性的、基于事实的回答
prompter = Prompt().load_model("bling-phi-3-gguf", temperature=0.0)
# `prompt_with_source` 是llmware的核心功能之一。
# 它会将我们上一步检索到的 `query_results` 作为上下文(Source),
# 连同我们的问题 `user_query` 一起,智能地打包成一个提示(Prompt),然后交给LLM处理。
responses = prompter.prompt_with_source(user_query, query_results=query_results)
# 打印最终生成的回答
print("\nLLM生成的最终回答:")
for i, response in enumerate(responses):
# response['llm_response'] 中包含了模型生成的最终答案
print(f"回答 {i+1}: {response['llm_response'].strip()}")
# 你还可以查看模型回答的“证据”是基于哪些文本片段
evidence = prompter.evidence_check_sources(responses)
print("\n回答的证据来源:")
for i, e in enumerate(evidence):
print(f"回答 {i+1} 的证据:")
for j, source in enumerate(e['source_review']):
print(f" - 证据 {j+1}: {source['text']}")
这个例子完整地展示了llmware的核心工作流程。通过替换文档路径和问题,你可以快速地将其应用于你自己的项目中。
应用场景
- 企业内部知识库问答系统一个公司内部有大量的规章制度、技术文档、项目报告和历史邮件。利用llmware,可以搭建一个内部的智能问答机器人。员工可以直接用自然语言提问,例如“公司的年假政策是怎样的?”或“上个季度的项目总结在哪里?”,机器人能够快速地从海量文档中检索信息并给出精准回答,所有数据和模型都在公司内部网络运行,确保了信息安全。
- 金融或法律文档分析助手金融分析师和律师需要阅读大量的财报、招股书、合同和判例文件。llmware可以被用来开发一个智能分析助手。这个助手可以快速解析上百页的PDF文档,并根据分析师的指令提取关键信息,例如“找出合同中关于违约责任的所有条款”或“总结这份财报中的主要风险点”。这极大地提高了专业人士的工作效率。
- 自动化客户支持许多公司的产品手册和帮助文档非常详尽。可以使用llmware将这些文档构建成一个知识库,并部署一个可以7x24小时服务的智能客服。当用户遇到问题时,例如“如何重置我的设备密码?”,智能客服可以根据帮助文档生成详细的操作步骤,分担人工客服的压力。
QA
- llmware支持哪些文档格式?llmware支持广泛的文档格式,包括PDF、Microsoft Word (.docx)、PowerPoint (.pptx)、Excel (.xlsx)、纯文本 (.txt)、Markdown (.md)、JSON、CSV,甚至还支持图片(.png, .jpg)和音频(.wav)文件。它能对这些文件进行深度解析,提取出文本、表格和图像内容。
- 使用llmware是否必须要有GPU服务器?不是必须的。llmware的一个核心优势就是它专注于使用小型的、在CPU上就能高效运行的模型。例如,其BLING和SLIM系列模型经过优化,可以在普通的笔记本电脑或标准服务器上运行,这大大降低了硬件门槛,让更多的企业和个人开发者可以使用。当然,如果你有GPU,也可以配置使用更大或更快的模型。
- llmware如何保证企业数据的安全性?llmware通过两种主要方式保证数据安全。首先,它是一个可以完全私有化部署的框架,你可以将它安装在自己的服务器上,整个数据处理流程(从文档解析、索引到模型推理)都在你的本地网络环境中完成,数据不会发送到任何第三方云服务。其次,它提倡使用本地化的小型模型,避免了对外部商业LLM API的依赖,从根本上杜绝了数据泄露的风险。